Overview
We received reports from end-users that a few client workstations on a specific subnet were experiencing around 70% packet loss when attempting to communicate between a few hosts. Since the initial report seemed to be rather isolated, we started with some basic ping tests, but as time went on and more hosts became affected, we started to escalate the issue and increasing our troubleshooting efforts.
Ping Tests
Take a look at the following ping samples from two different sources to different targets that were passing traffic on the switch in question:
-bash-4.1$ ping host1
PING host1 (1.2.3.4) 56(84) bytes of data.
64 bytes from host1 (1.2.3.4): icmp_seq=1 ttl=128 time=1.51 ms
64 bytes from host1 (1.2.3.4): icmp_seq=35 ttl=128 time=0.291 ms
64 bytes from host1 (1.2.3.4): icmp_seq=36 ttl=128 time=0.361 ms
64 bytes from host1 (1.2.3.4): icmp_seq=37 ttl=128 time=0.400 ms
64 bytes from host1 (1.2.3.4): icmp_seq=38 ttl=128 time=0.264 ms
64 bytes from host1 (1.2.3.4): icmp_seq=39 ttl=128 time=0.356 ms
64 bytes from host1 (1.2.3.4): icmp_seq=40 ttl=128 time=0.419 ms
64 bytes from host1 (1.2.3.4): icmp_seq=41 ttl=128 time=0.260 ms
64 bytes from host1 (1.2.3.4): icmp_seq=42 ttl=128 time=0.349 ms
64 bytes from host1 (1.2.3.4): icmp_seq=43 ttl=128 time=0.416 ms
64 bytes from host1 (1.2.3.4): icmp_seq=44 ttl=128 time=0.429 ms
64 bytes from host1 (1.2.3.4): icmp_seq=45 ttl=128 time=0.314 ms
64 bytes from host1 (1.2.3.4): icmp_seq=46 ttl=128 time=0.359 ms
64 bytes from host1 (1.2.3.4): icmp_seq=47 ttl=128 time=0.447 ms
64 bytes from host1 (1.2.3.4): icmp_seq=48 ttl=128 time=0.287 ms
64 bytes from host1 (1.2.3.4): icmp_seq=49 ttl=128 time=0.405 ms
64 bytes from host1 (1.2.3.4): icmp_seq=50 ttl=128 time=0.416 ms
^C
-bash-4.1$ ping host2
PING host2 (2.3.4.5) 56(84) bytes of data.
64 bytes from host2 (2.3.4.5): icmp_seq=1 ttl=128 time=1.21 ms
64 bytes from host2 (2.3.4.5): icmp_seq=30 ttl=128 time=0.484 ms
64 bytes from host2 (2.3.4.5): icmp_seq=59 ttl=128 time=0.467 ms
64 bytes from host2 (2.3.4.5): icmp_seq=83 ttl=128 time=0.197 ms
64 bytes from host2 (2.3.4.5): icmp_seq=84 ttl=128 time=0.241 ms
64 bytes from host2 (2.3.4.5): icmp_seq=85 ttl=128 time=0.210 ms
64 bytes from host2 (2.3.4.5): icmp_seq=86 ttl=128 time=0.240 ms
64 bytes from host2 (2.3.4.5): icmp_seq=87 ttl=128 time=0.171 ms
64 bytes from host2 (2.3.4.5): icmp_seq=88 ttl=128 time=0.216 ms
64 bytes from host2 (2.3.4.5): icmp_seq=89 ttl=128 time=0.194 ms
64 bytes from host2 (2.3.4.5): icmp_seq=90 ttl=128 time=0.392 ms
64 bytes from host2 (2.3.4.5): icmp_seq=91 ttl=128 time=0.240 ms
64 bytes from host2 (2.3.4.5): icmp_seq=92 ttl=128 time=0.235 ms
64 bytes from host2 (2.3.4.5): icmp_seq=93 ttl=128 time=0.222 ms
^C
The first response in both samples take a little longer than what we expected for two hosts connected to a local Gigabit switch, but falls within the profiled delay for ARP resolution. After the longer initial ping response time, all subsequent pings fall within the expected value for the local network.
The TTL values all look normal so we know the traffic isn’t leaving the local network and hitting additional hops, but take a look at the sequence numbers; they are not sequential and show a sign of a larger problem.
In the first sample, sequence numbers 2-34 were lost as were 2-29 in the second sample. We know that around 30 seconds of traffic was being completely lost in both test cases.
Find the Layer
At this point we could rule out a Layer 1 issues so we knew there was no issue with our optics being dirty or the input/output queues on any of the switching equipment.
There had to be a Layer 2 issue, which could include bridging, MAC address learning occurring on different pieces of equipment at different times, competition for an IP, or ARP poisoning.
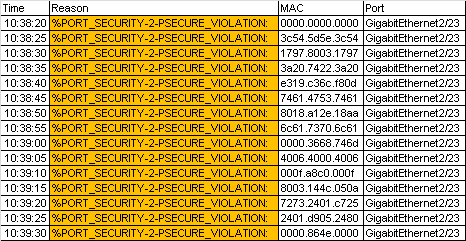
As more time passed, more workstations started to notice more loss of traffic on the network. All signs pointed to something wrong with the ARP table. A show mac address-table command on one of the switches showed that a number of hosts were associated with a MAC address of 00:00:00:00:00:00 and that number was increasing over time.
Wireshark
After getting a SPAN port on the switch and looking at traffic with Wireshark, we found a large number of responses to ARP requests with a value of 00:00:00:00:00:00 for hosts in the local subnet that were all sourced from one machine. This one computer was poisoning the ARP cache on the network with all zeros, causing the location for every host to eventually become a blackhole for traffic.
As more ARP caches on end-user machines and switching equipment were timing out, they were sending out new ARP requests and getting poisoned information. Once the offending machine’s port was shut down, we started to notice traffic return to normal.