I come from a background of enabling office users with Internet access for general business purposes with ingress traffic filtering and NAT services being handled at the border with a firewall appliance. Over the past few months, I’ve had to shift my paradigm to one that doesn’t contain a stateful ingress filtering firewall, which has been a culture shock for my Cisco “Defense in Depth” ideals.
Part of my focus at Berkeley Lab is to enable scientists with the ability to transfer large amounts of research datasets over the network. Their transfers may remain locally within our laboratory campus, transverse the San Francisco Bay Area, or end up going across the globe to institutions located many miles away. These three types of transfers all present the same challenge of keeping total RTT low, making sure that interface buffers are undersubscribed, and maintaining an ideal zero packet loss for the transmission.
Science DMZ Architecture
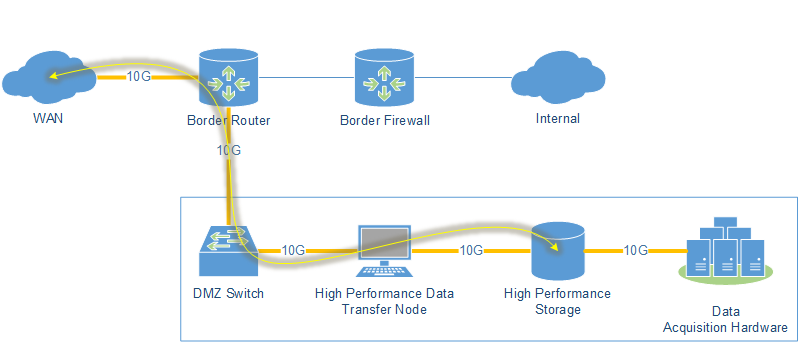
The Science DMZ architecture, coined by collaborators in 2010 from the US Department of Energy’s Energy Sciences Network (ESnet), enables us to approach 10G transfers speeds for our scientists. The design calls for the network to be attached to the border router, disparate from the stateful firewall protected Internal network, with end-to-end 10G connectivity between the WAN and the storage network with a Data Transfer Node (DTN) facilitating transfers.

With this architecture, data acquisition and data transfer steps are separated into two discrete processes:
- First the acquisition hardware, which could be a camera, sensor, or other recording device, writes information to a local storage array. This array is usually Solid State in order to accommodate the volume of the incoming data stream(s).
- The second step is to transfer the data to high performance processing nodes that are not contained in the Science DMZ. The transfer method in this step could be single-stream FTP, parallel-stream GridFTP, or SaaS transfers to locations like Globus.
The workflow that we have seen scientists operate under is that they will often discard or re-sample datasets and only send a fraction of the captured data for processing to offsite nodes. With this two step process, the amount of data that goes offsite for processing is reduced as it has already been pre-filtered by the scientists.
Case Study
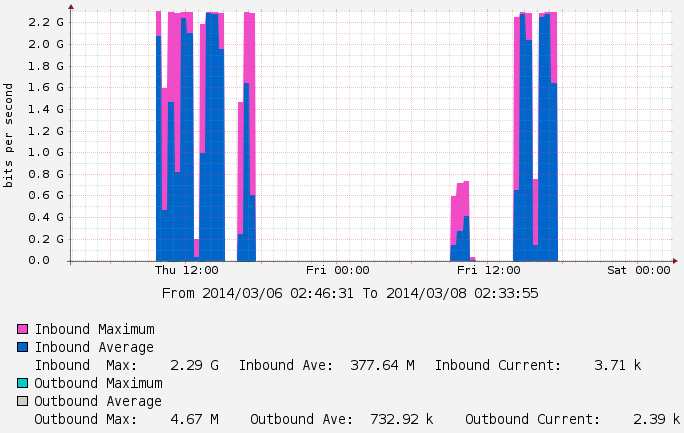
Below is a sample of a recent transfer conducted on one of our Science DMZ networks that is connected at 10G speed. As you can see the performance is far below the expected theoretical max. There are many pieces of equipment that needs to be optimized in order to achieve near-10G speeds:
- Storage Array I/O
- File System on the Array
- NIC on the DTN
- Buffers on the DMZ Switch
- Buffers on the Border Router
- End-to-end Jumbo Frames
- Transfer Protocol
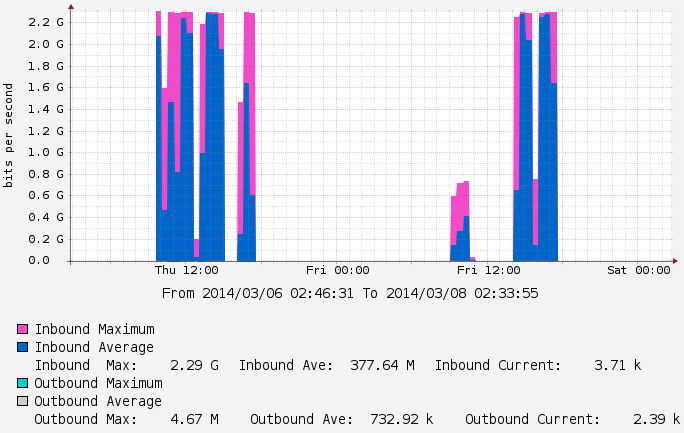
In this case we found that the local storage array was not able to saturate the network even with 16x1TB SSDs running in RAID5. The resulting transfers peaking around 2.3 GBPS; our tests with perfSONAR showed that our network equipment is capable of pushing up to 9 GBPS.
Achieving 10 Gigabit speeds on a host-to-host transfer is not as simple as I thought as it requires the optimization along many layers of hardware and software. For further information, a detailed list of client optimization steps can be found on the Network Tuning page at fasterdata.es.net.